I rebuilt Voicy with agents instead of rewriting it myself
How I used Symphony, OpenClaw, Codex, a home server, Telegram Web QA, and a Windows GPU worker to revive Voicy as an agent-driven maintenance loop.


I did a funny 180.
In March 2025 I published “I’m sunsetting Voicy”. The code stayed open source and the hosted bot kept running, but I was tired of maintaining it as a side project.
Then speech tech moved forward, privacy started mattering even more, and I realized Voicy could be a better bot if I rebuilt the boring parts around local workers, stronger queues, better tests, and clearer operational boundaries.
So over the last week I rebuilt the whole thing. Not by sitting down for one heroic rewrite. I rebuilt it by turning the project into an agent loop.
The important part is that I mostly interacted with the system like an executive, PM, or tech lead. I told OpenClaw what I wanted in Telegram, dropped screenshots and corrections into the chat, and the setup turned that into Kaneo tasks, Symphony runs, Codex PRs, OpenClaw QA through Codex Computer Use, deploys, and review decisions. I was not opening Kaneo, manually grooming cards, or sitting there as the QA person.
The current setup is:
- Kaneo is the backlog and task state.
- Symphony watches Kaneo, routes tasks into isolated repo workspaces, and starts Codex.
- Codex does scoped implementation, tests, commits, and PR handoff.
- OpenClaw supervises from Telegram, reads context, manages Kaneo tasks, handles credentials, uses Codex Computer Use for browser/manual QA, deploys when appropriate, and merges/moves tasks when the proof is good.
- Voicy is now a normal bot backend plus a Windows GPU worker doing Whisper transcription.
This is the part of AI coding nobody likes to screenshot because it is not sexy. It is task state, repo routing, test gates, PR review, Telegram Web QA, Windows scheduled tasks, Mongo indexes, logs, retries, and a lot of “why the hell is this one voice message still queued?”
What I wanted
I did not want “AI writes code in my repo while I watch it hallucinate.” I wanted something much more boring and much more useful:
A task should be created once, picked up automatically, worked on in the right repository, verified, opened as a PR, reviewed, manually QA’d when needed, deployed when appropriate, and then moved to done. The human should be able to steer from Telegram without becoming the CI server, the PM tool, the reviewer, the Kaneo operator, and the deployment checklist.
Not a chat. A loop.

The important shift is that the prompt is not the source of truth anymore. The board is. The task has the title, acceptance criteria, repo hints, validation requirements, and review state. Symphony is allowed to act only on active states like to-do, in-progress, and rework. Backlog stays backlog. Done is done.
I use self-hosted Kaneo for this instead of Linear because I need the boring thing to be fast, cheap, local to my setup, and API-shaped. Linear is a great product, but here I mostly need a simple Kanban board with states, tasks, comments, and an API. Kaneo gives me that without per-seat SaaS pricing, without depending on a multi-tenant service path, and without extra product surface I am not using.
This is what that looks like in practice. Kaneo is not the place where I manually plan my day. It is the state machine OpenClaw and Symphony use to know what exists, what can be picked up, what needs review, and what is already done.
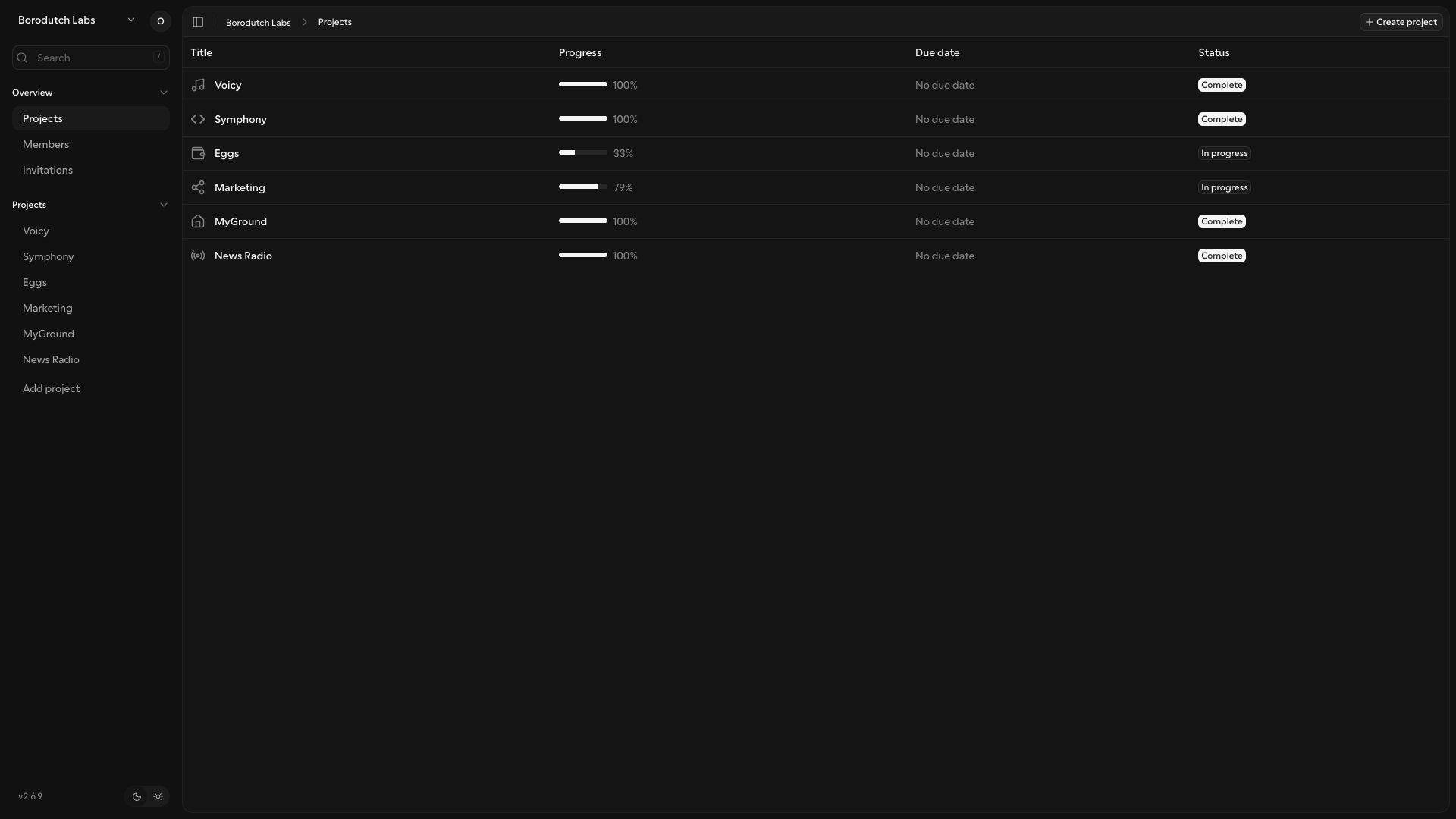
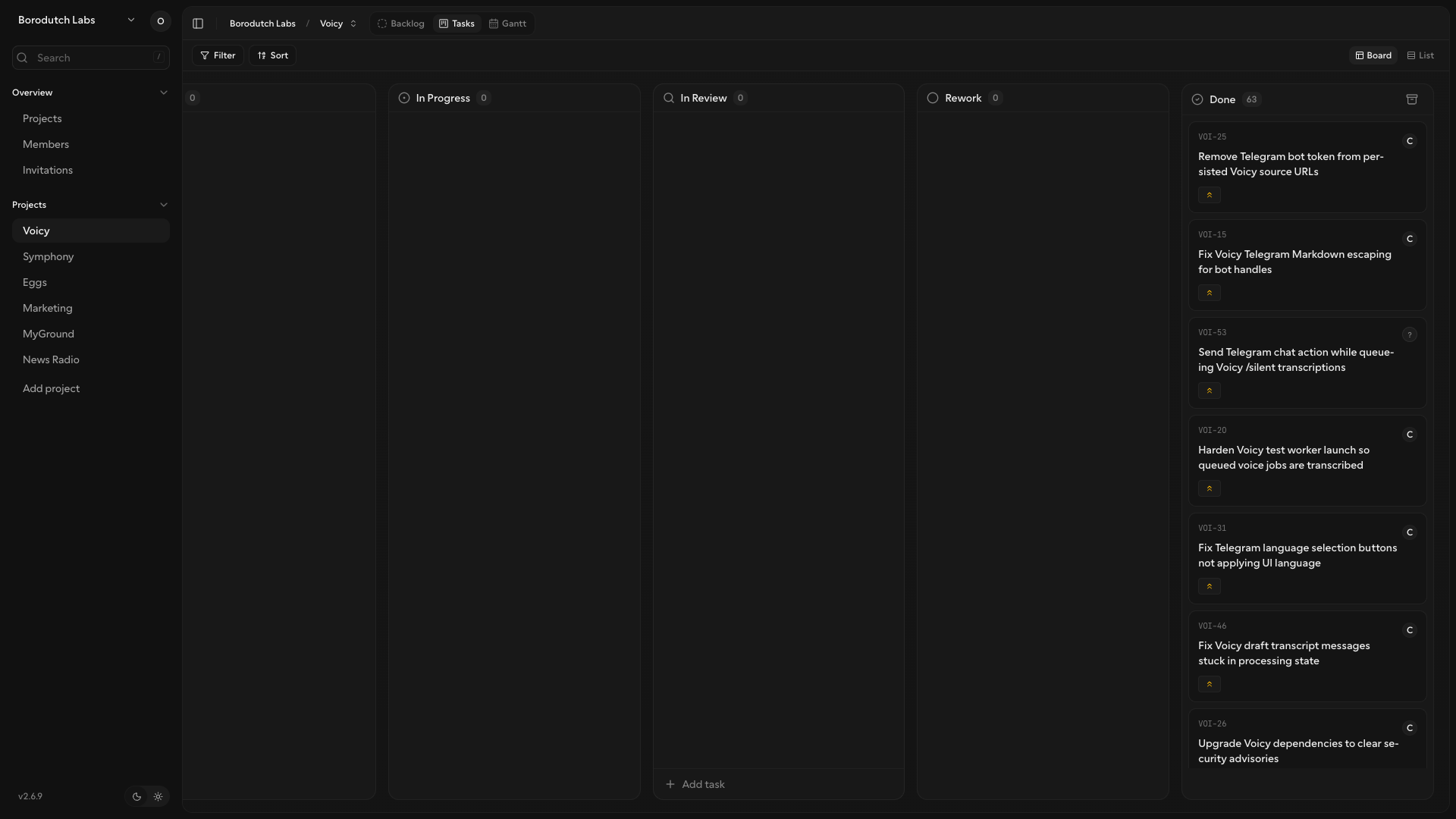
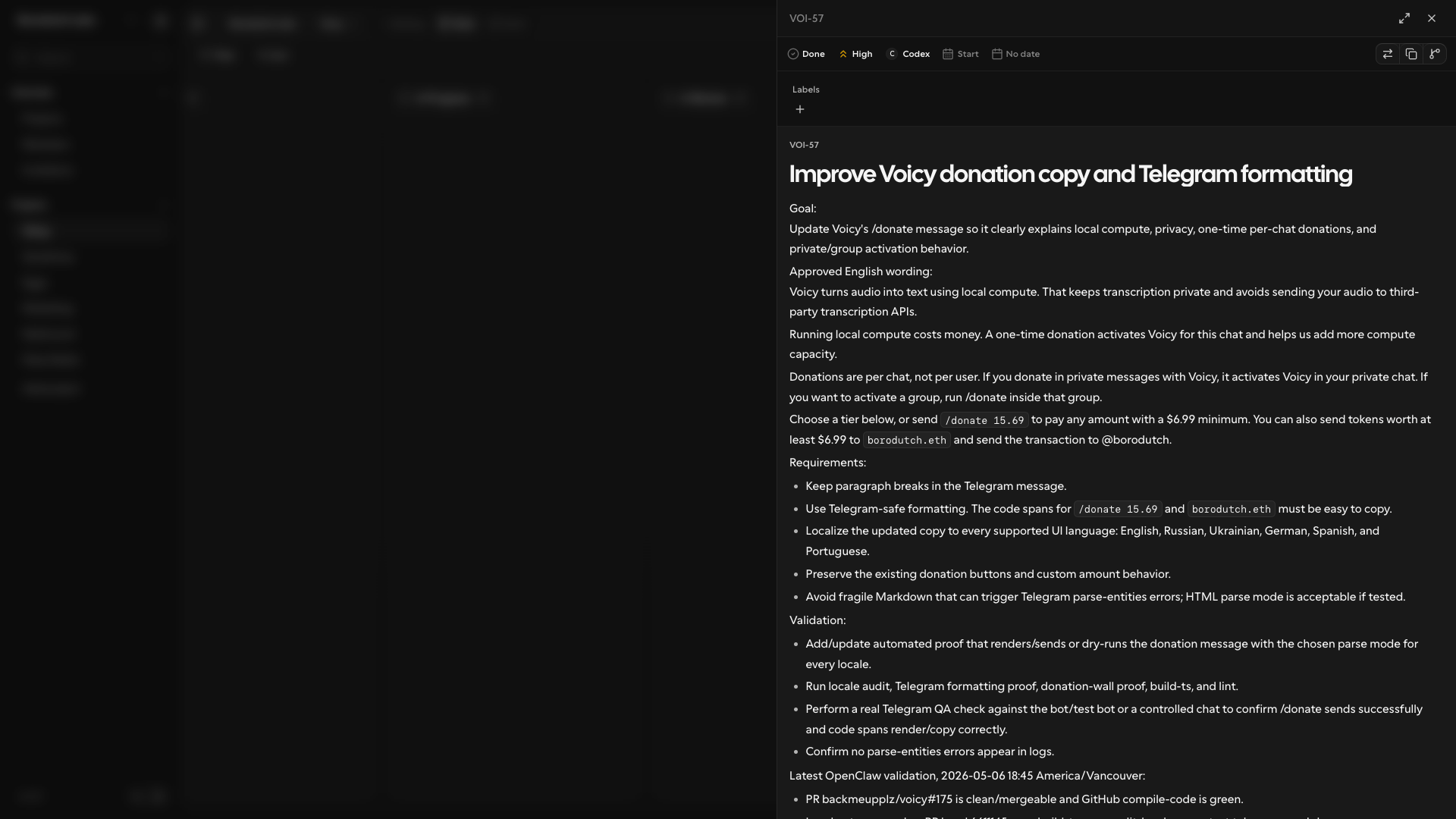
My local Symphony workflow currently routes a big set of projects, not a single repo. Voicy goes to backmeupplz/voicy, Symphony goes to backmeupplz/symphony, Eggs can route to backend/frontend/archive repos, Marketing can route to notes/profile/website/stats repos, and so on. The runner injects the selected repo metadata into the workspace hook, clones only what the task needs, and then starts Codex with the expected model and permissions.
tracker:
kind: kaneo
endpoint: "https://kaneo.example.internal/api"
projects:
- slug: voi
repo_url: "https://github.com/backmeupplz/voicy"
repo_ref: "main"
- slug: sym
repo_url: "https://github.com/backmeupplz/symphony"
repo_ref: "main"
workspace:
root: ~/code/symphony-workspaces
codex:
command: codex --config 'model="gpt-5.5"' --config model_reasoning_effort=high app-server
approval_policy: neverYes, the agent has wide local permissions. No, this does not mean it is allowed to publish, email, tweet, or push secrets into screenshots. The external boundary matters more when the local permissions are powerful.
The infra
This is the actual home setup. I am not pretending it is a clean SaaS diagram.
- Home server: MyGround, my self-hosted personal cloud and ops base, running services over Tailscale: Kaneo, Penpot, Vaultwarden, and other internal tools.
- MacBook: OpenClaw with broad local permissions, Codex Computer Use for browser/manual QA, Symphony running locally, a logged-in Telegram Web QA Chrome profile, Ghost/Penpot credentials in Vaultwarden, and access to the repos.
- Windows machine:
borodutch-pcwith an RTX 4070 Ti, a nativeC:\voicy-workercheckout, Python 3.11, FFmpeg, CUDA/cuDNN wheels,faster-whisper, and a scheduled task calledVoicyWorker4070Ti. - Voicy bot runtime: Node backend, MongoDB, Telegram bot webhook/runtime, authenticated worker API, and worker clients polling jobs.
The Mac is the command center. The Windows machine is the GPU mouth. The home server is the boring stateful middle. Telegram is the place where I yell at the whole thing when it acts like a distributed systems textbook.

What changed in Voicy
Between May 1 and May 7, 2026, Voicy had 62 PRs from #121 through #182. That is the receipt trail for the rebuild: small scoped changes, review handoffs, QA notes, and mergeable units instead of one giant rewrite branch.
The useful part is not the number. The useful part is the shape of the work:
- dependency refresh and build/lint cleanup
- Telegram Markdown escaping and command alignment
- real Telegram Web QA helper for text and upload flows
- local Whisper proof, then authenticated Windows GPU worker docs
- worker API tests, media coverage, local file download by workers
- configurable STT model selection
- security audit, token-bearing URL removal, sanitized logging
- abuse limits and better error handling
- donation tiers, Golden Borodutch subscriber grants, support copy
- Ukrainian, German, Spanish, and Portuguese UI languages
- Telegram 429 retry handling, stale update replay prevention, unreachable-chat handling
- transcript formatting, silent mode races, status copy, and final result logging
- transcription result cache and active-job dedupe by Telegram media cache key
The donation system also changed shape. Voicy’s /donate flow is not just a paywall; it is a way for a chat to buy more compute for transcription. More paid usage means more room to add worker capacity, which is what keeps local transcription fast instead of turning the bot into a slow shared queue.
This is exactly the kind of maintenance pile that makes old projects feel expensive to keep alive. None of these tasks is a billion-dollar research problem. But together they are the difference between “open source bot I am tired of babysitting” and “private, robust speech infrastructure I actually want to run.”
The main loop
Here is the loop that worked best.
- I tell OpenClaw in Telegram what needs to happen, often with screenshots or rough product judgment.
- OpenClaw investigates, creates and updates Kaneo tasks, and keeps the board moving without me opening Kaneo.
- Symphony sees tasks in active states and creates isolated workspaces under
~/code/symphony-workspaces. - Codex implements in the cloned repo only.
- Codex leaves a workpad and opens a normal GitHub PR with validation and testing handoff.
- OpenClaw monitors review-ready work, checks PRs, runs missing local/manual QA through Codex Computer Use, merges or sends work back to rework, deploys when the change needs deployment, verifies the result, and only then moves the task toward done.
That is the devshop-shaped part. OpenClaw is the PM/tech-lead surface in Telegram and the thing that manages the board for me. Kaneo is the source of truth, but I usually do not touch it directly. Symphony is the dispatcher. Codex is the implementation worker. OpenClaw comes back as reviewer, QA, deployer, and closer when the code-side proof is not enough.
In other words, AI can create the tasks, complete the tasks, monitor which tasks need review, QA the tasks, merge the PRs, and deploy the changes. I still make product calls and set boundaries, but the normal delivery loop is not waiting for me to click through Chrome.
Symphony’s own dashboard is wonderfully unromantic. It shows what matters: running sessions, retry pressure, token usage, runtime, and the active issue. This capture shows one Voicy task, VOI-KANEO-59, chewing through the local Telegram Bot API problem.
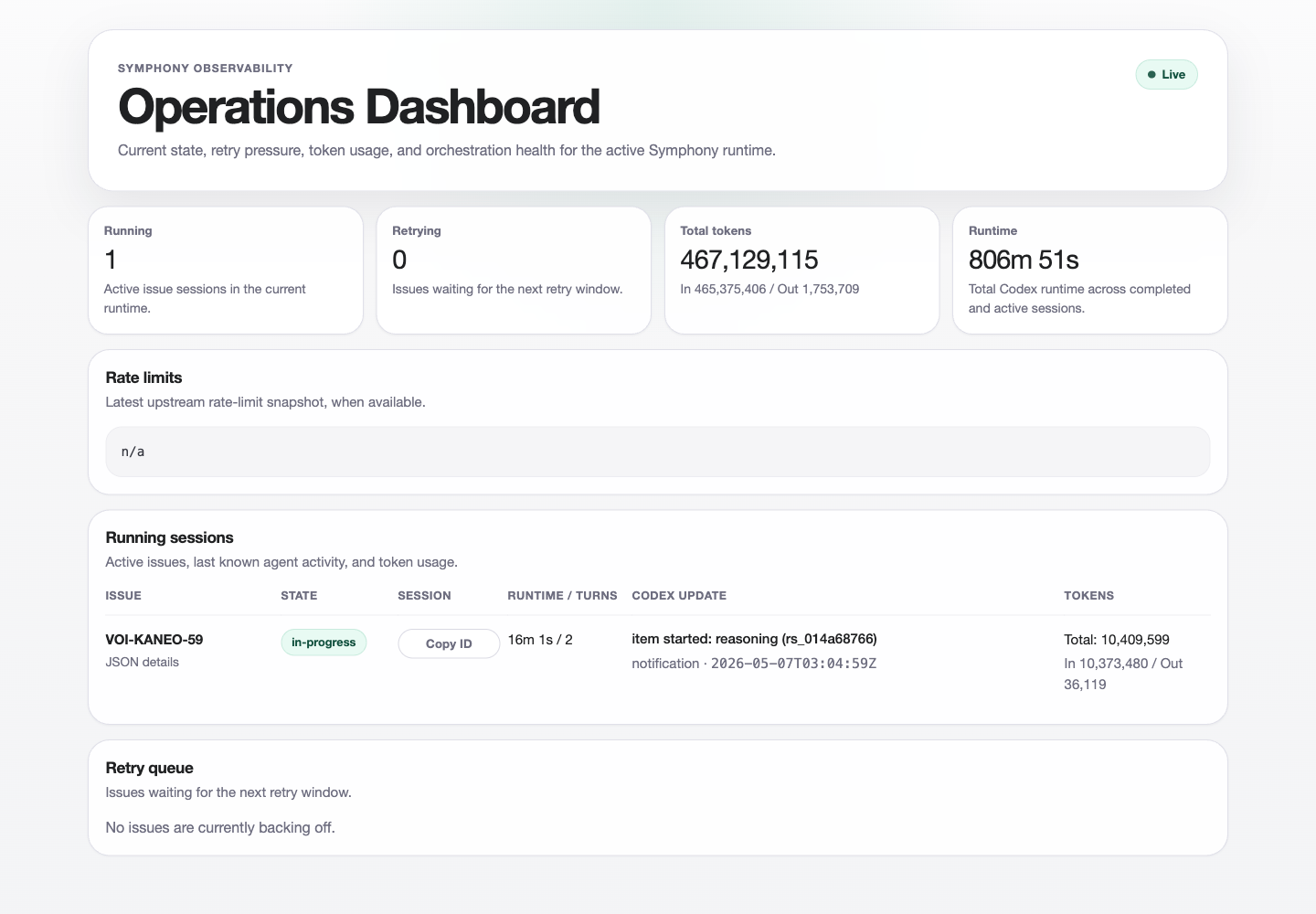
One important rule: if a task needs browser login state, Telegram Web, mobile, a real device, payment checkout, or a local app, the agent must say so. Automated tests are not allowed to magically imply manual QA.
I had to patch Symphony itself for that. PR #7 made testing handoffs mandatory and split automated validation from manual QA. PR #8 cleaned up merged PR branches after handoff. Earlier, PR #1 and PR #2 fixed Kaneo review/running-state behavior so the runner did not leave handoffs active forever.
I would not tell anyone to blindly copy my Symphony fork. It is already opinionated around my machine, my projects, my Kaneo states, my Telegram/OpenClaw flow, and my tolerance for local permissions. The useful move is to treat the runner as part of the system you customize. I have a separate Kaneo project called “Symphony” where OpenClaw creates tasks for the fork, Symphony/Codex implement them, and OpenClaw reviews the result. The delivery loop is also how the delivery loop gets better.
Telegram QA or it did not happen
Telegram bots are annoying to test honestly. You can unit test handlers all day, but if the real Telegram Web UI cannot send a command, attach a file, receive a status update, and display the final answer, you are lying to yourself.
For Telegram QA, OpenClaw uses Codex Computer Use to drive Chrome with a logged-in test Telegram account. It can open Telegram Web, send commands to bots, upload files, send voice messages, read the replies, and check the actual behavior in the UI. A scripted helper like scripts/telegram_web_qa.mjs is useful for repeatable checks, but the important capability is that the AI can operate the real browser session without me in the loop.
node scripts/telegram_web_qa.mjs \
--browser-url http://127.0.0.1:9222 \
--chat @username \
--send \
--message "Voicy Telegram QA 2026-05-07T03:04:59Z" \
--verify-text "Voicy Telegram QA" \
--json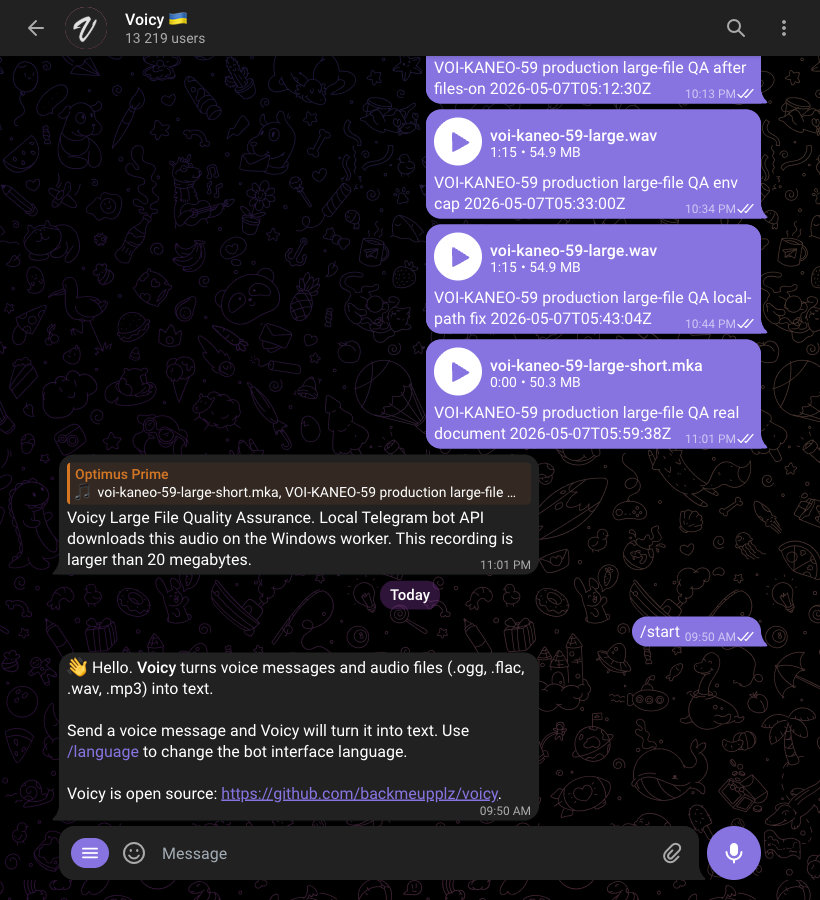
This became a hard rule after I got burned by code-side “proof” that did not prove the user-facing behavior. For Telegram work, the PR can pass build, lint, worker tests, and scripted API checks, but it still needs Telegram Web proof if the UI changed. The point is not that I manually test it. The point is that OpenClaw can use Codex Computer Use to test it the way a user would.
The Windows worker
The worker is the part that made Voicy worth modernizing.
The Mac can run local Whisper, but the Windows box has the RTX 4070 Ti. So the bot backend creates authenticated transcription jobs, and the Windows worker polls, downloads media, runs faster-whisper with large-v3 on CUDA/float16, and posts the result back.
I should stress how weird this is for me personally: I have never developed on Windows. Ever. I did not even know Windows had native OpenSSH available. Now OpenClaw drives that Windows machine over SSH, checks whether the worker is alive, inspects logs and scheduled tasks, diagnoses CUDA/path/service problems, patches the setup, reruns jobs, and tells me whether the whole thing actually works.
Conceptually, this is the same feature people know from Telegram Premium voice-to-text: voice goes in, text comes out inside Telegram. Telegram exposes voice-message transcription through its own API, but does not publicly name the underlying model. My version uses local Whisper via faster-whisper, which gives me the same kind of user-facing behavior while keeping the transcription worker under my control.
The first version failed in boring ways. The useful part is that the loop fixed these without me jumping in to debug the worker by hand:
- an old Mac launchd worker was still alive and stealing jobs;
VOICY_WORKER_LANGUAGE=autowas being treated like a literal language;- PowerShell shifted empty arguments in a way that made the model name look like a language;
- CTranslate2 could not find
cublas64_12.dlluntil CUDA DLL directories andPATHwere fixed; - large Telegram files hit the normal Bot API download limit, which led to the local Telegram Bot API task.
The worker now runs as a Windows scheduled task, and the old Mac worker was disabled. The AI-driven loop found the stale worker, fixed the language/config bugs, patched the Windows CUDA path, reprocessed failed voice jobs, and completed test jobs in English and Russian without me intervening. The next infrastructure edge was large Telegram media: the normal Bot API download path caps out, so the loop produced a local Telegram Bot API path for downloading larger files directly when credentials and rate limits allow it.
I have not written a single line of code for any of these fixes. The only way I fixed them was by talking through the problem with OpenClaw in Telegram: “this failed,” “check the worker,” “make sure the bot really replies,” “deploy it.” OpenClaw turned that into Kaneo tasks, Symphony and Codex worked through the code, and OpenClaw verified the result.
This is another thing I like about the loop: blockers become work, not meetings. The agent does not have to pretend. It can say “the binary is built, the scheduled task is not registered yet,” then create the next task, fix the scheduled task, rerun QA, and keep going. A human only needs to enter the loop for genuinely external decisions, unavailable credentials, or product judgment.

Other projects kept moving
One thing I wanted from this setup was motion across a big set of projects. If the whole system only works for one repo, it is a demo. My life is not one repo.
While Voicy was being modernized, the same loop was working on Eggs shutdown tasks. Eggs is a good example of why repo routing matters: backend, frontend, archives, contract assumptions, wallet flows, deploys, and manual QA all matter.
For the Eggs wind-down rewrite, I only gave OpenClaw the high-level requirement in Telegram: wind the app down to the shutdown wallet flows. I did not manually find the repos, create the project plan, split the tickets, or sit in the review loop. OpenClaw found the right repos, created the Kaneo project/tasks, Symphony and Codex completed the implementation work, the deploy path was handled, and OpenClaw checked and verified the result.
I do not want agents that wander across my whole machine trying to be clever. I want them scoped to the task’s repos. If a task says backend and frontend, clone both. If it says Voicy, do not touch Eggs. This sounds obvious until you try to run agents across a messy set of projects.
The hurdles
The hardest parts were not “can the model write TypeScript?” The hard parts were all the things around the code.
State
At first, tasks could get stuck in the wrong board state. Review handoffs stayed active. Running work needed to remain claimed. Symphony had to learn that backlog is not executable, done is terminal, and retry/rework needs continuation rather than starting from scratch.
Repo routing
Single-repo demos are easy. Real products have backend, frontend, archive repos, stats repos, marketing repos, and the occasional local-only repo. The workflow now supports SOURCE_REPO_KEY, SOURCE_REPO_KEYS, explicit repo URLs, defaults, and generated workspace metadata. The agent gets the repo scope instead of guessing.
QA
The agent can run yarn build-ts, yarn lint, worker tests, Mongo-backed worker API tests, PowerShell parser checks, and deterministic unit tests. It cannot truthfully claim that Telegram Web displayed the right thing unless something actually looked at Telegram Web.
That is why OpenClaw owns manual/browser/device QA. It has access to Codex Computer Use, the real logged-in Telegram QA profile, screenshots, cropping/redaction tools, and enough local context to leave final proof instead of vibes. It can send a bot /start, upload a voice message, wait for a transcription, inspect the reply, and decide whether the task is actually reviewable or needs rework.
Secrets
Wide local permissions are useful and dangerous. Credentials live in Vaultwarden, the self-hosted password manager I use here like a private 1Password for OpenClaw. I only share the specific credentials this loop needs, so OpenClaw can fetch a Ghost, Penpot, Stripe, or deployment secret when the task requires it without giving the agent access to unrelated accounts. Draft images get privacy passes. Screenshots are cropped. Logs are sanitized. Token-bearing Telegram file URLs had to be removed from Voicy source URLs and reports. The more autonomous the loop is, the more boring credential hygiene has to be.
Rate limits and external reality
Telegram 429s are real. my.telegram.org rate limits are real. Stripe checkout behavior is real. Chrome profile state is real. Windows Edge locking its cookie DB over SSH is very real. These are not model problems. They are reality problems.
Tinkering
This still required a lot of tinkering. I had to shape the task states, repo routing, QA rules, credentials, browser profiles, worker machines, and review expectations while the system was already doing useful work. But that is the interesting trend: the more I use OpenClaw, Symphony, and Codex together, the more those corrections become tooling and workflow, and the less the next task needs me in the middle.

How to copy it
You do not need my exact stack. The pattern is the useful part.
- Pick a real backlog. Kaneo works for me because it is self-hosted, fast, and API-first enough for a simple board. GitHub Issues, Linear, or any API-backed tracker can work too. The tracker must have states and task descriptions that agents can read.
- Make task state authoritative. Decide which states are executable, which states are review-only, and which state is terminal.
- Give each project repo metadata. At minimum: repo URL, base ref, slug, and optional repo keys for multi-repo projects.
- Create isolated workspaces. One task, one folder, one branch. Do not let runs share random dirty working directories.
- Start the coding agent with a narrow contract. It should know the issue, the cloned repo scope, the validation requirements, and the rule that it must not invent manual QA.
- Require a workpad and PR handoff. A useful agent leaves receipts: what it changed, what it ran, what passed, what is blocked, and what manual QA remains.
- Separate automated validation from real-world QA. Browser login, Telegram, payments, mobile, GPU machines, and local devices need explicit proof. Use Codex Computer Use or an equivalent browser/device agent path so QA can happen without a human clicking through the app.
- Customize the runner. Do not blindly use my Symphony fork. Use OpenClaw and Codex to adapt your runner to your board states, repo topology, QA expectations, permissions, and deployment path.
- Keep credentials out of the repo. Use a password manager or secret store. Never paste tokens into tasks, screenshots, or PR bodies.
- Automate the boring watchdogs. Poll for stuck runners, retrying jobs, stale workers, pending queues, and PRs waiting on review.
- Turn blockers into work. If the agent finds the exact credential, rate limit, hardware access, or runtime problem, that should usually become the next task automatically, not a meeting. Pull in a human only for real external decisions, unavailable credentials, or product judgment.
The minimal version can be just:
# 1. Create a task with acceptance criteria.
# 2. Clone the repo into a task-specific workspace.
mkdir -p ~/code/agent-workspaces/VOI-123
git clone [email protected]:backmeupplz/voicy.git ~/code/agent-workspaces/VOI-123
# 3. Start your coding agent with the task context.
cd ~/code/agent-workspaces/VOI-123
codex --config 'model="gpt-5.5"' --config model_reasoning_effort=high app-server
# 4. Require tests, a PR, autonomous QA proof, and deploy verification before done.Then make it less manual one piece at a time. Tracker polling. Workspace creation. Repo routing. PR creation. Review checks. Browser QA. Worker health. Do not start by building the whole cathedral.
What I learned
The workflow is simple to describe now. I tell OpenClaw in Telegram what outcome I want. OpenClaw investigates, creates Kaneo projects and tasks, decides what is backlog, review, rework, or done, and hands coding tasks to Symphony. Symphony starts Codex in scoped workspaces. Codex writes code, runs tests, and opens PRs. OpenClaw watches review queues, uses Codex Computer Use for real Telegram and Chrome QA, sends work back when it fails, merges when the proof is good, deploys when required, and verifies the result. I manage the PM-ish agent; the PM-ish agent manages the coding agents.
The biggest productivity jump was not a better autocomplete. It was moving the model into a system where unfinished work has a place to live.
What I learned is uncomfortable: AI is good enough to replace a whole small company of developers for this kind of work. Not just autocomplete. Not just one coding agent waiting for a ticket. The loop is good enough to work autonomously once it has task state, credentials, repo boundaries, QA rules, and deploy paths.
We jumped from AI code autocomplete to AI coding agents. The next jump is already happening: from managing coding agents directly to managing PM-ish AI agents that manage coding agents for you. That is what OpenClaw is in this setup. It is the Telegram-facing PM/tech-lead layer that turns intent into tasks, task state, code work, QA, merge decisions, and deploy verification.
There is no realistic way to keep up by reading all the code in this loop. There is too much code and there are too many PRs. Also, frankly, AI is now better at reviewing PRs, chasing regressions, and doing repetitive QA than any human trying to supervise a big set of projects by hand. The human job shifts from reading every diff to setting boundaries, evaluating outcomes, and deciding what matters.
My guess is that very few people, probably fewer than a few dozen, are fully embracing a complete AI-agent dev cycle like this. “Vibe coding” became “agentic engineering,” and then “full-cycle dev team work,” in under six months. It is moving so fast that most people are not even trying to keep up.
If you want to stay relevant, you have to keep up. Not with every repo, PR, or implementation detail. With the workflow shift itself.
That is the part I want other builders to steal.